Conditional Plane-based Multi-Scene Representation for Novel View Synthesis
for Novel View Synthesis
Abstract
Existing explicit and implicit-explicit hybrid neural representations for novel view synthesis are scene-specific. In other words, they represent only a single scene and require retraining for every novel scene. Implicit scene-agnostic methods rely on large multilayer perception (MLP) networks conditioned on learned features. They are computationally expensive at training and rendering times. In contrast, we propose a novel plane-based representation that learns to represent multiple static and dynamic scenes during training and renders per-scene novel views during inference. The method consists of a deformation network, explicit feature planes, and a conditional decoder. Explicit feature planes are used to represent a time-stamped view space volume and a shared canonical volume across multiple scenes. The deformation network learns the deformations across shared canonical object space and time-stamped view space. The conditional decoder estimates the color and density of each scene constrained on a scene-specific latent code. We evaluated and compared the performance of the proposed representation on static (NeRF) and dynamic (Plenoptic videos) datasets. The results show that explicit planes combined with tiny MLPs can efficiently train multiple scenes simultaneously. The project page: https://anonpubcv.github.io/cplanes.
| Our results - multi scene |
|
|




|
Scene Dimention
Visualization of multi-scene representation. The slider includes the novel views rendered by the proposed representation for a fixed camera pose with different auto-decoded latents.
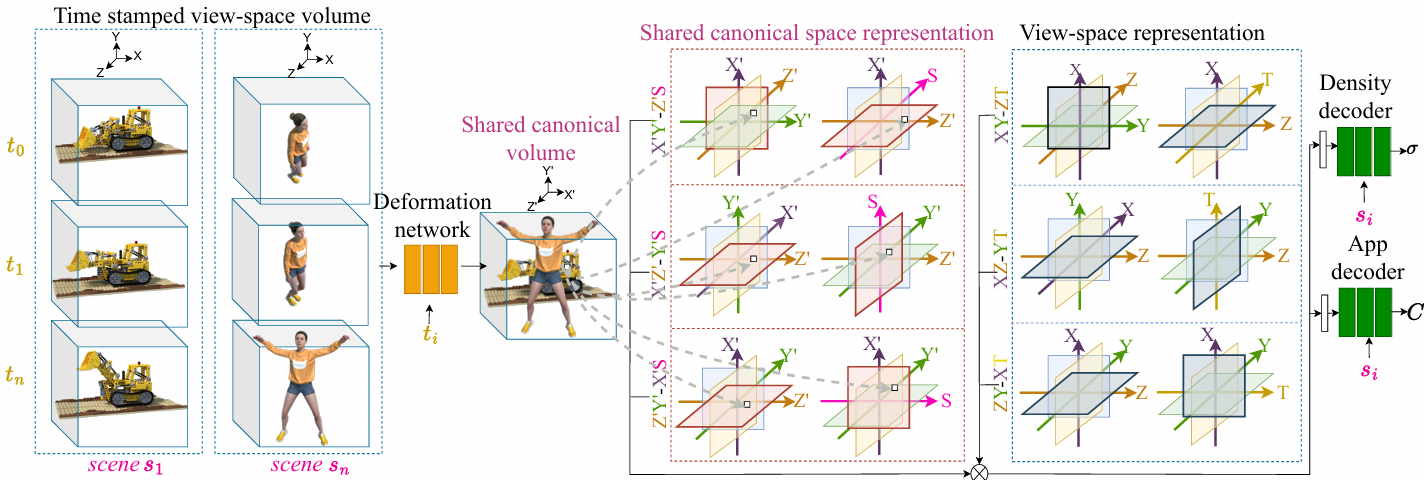
The method consists of four components: (1) a shared canonical space representation, (2) a deformation network, (3) a view-space representation, and (4) a conditional MLP decoder.